
Part1 : SECloudit 이론
1. SECloudit이란?
SECloudit란 Cloud Native Application개발과 운영을 위한 최적의 PaaS 플랫폼을 말하며,
Shift + Enter의 합성어로 개발자에게 새로운 환경을 제공한다는 의미를 갖고 있다.
2. SECloudit의 장점
- SECloudit는 CLI가 아닌 편의성이 극대화된 GUI 기반의 환경에서 통합을 위한 빌드 기능을 제공하고 있다.
- Tekton 기반의 빌드/배포에 최적화된 CI/CD 파이프라인 기능을 제공하고 있다.
- 역할 기반 사용자 관리 기능을 제공하여 원활한 K8S 운영이 가능하다.
- 오토 스케일러를 통해 증가하는 요구사항에 대한 서비스 안정성 확보 가능.
- 쿠버네티스 클러스터 구성 현황을 한눈에 볼 수 있는 글로벌 모니터링 대시보드 제공

※ SECloutit 시스템 개요

- Kubernetes 워크로드 관리 기능 (워크로드 제어 및 관리 / 모니터링 / 클러스터 관리 및 모니터링 / 대시보드)
- DevOps 특화 기능 (CI/CD 파이프라인[GitLab CI - Argo CD] / Openshift 이미지 빌드 기반)
- Kybenetes-Native 특화 기능 (K8S환경에서의 Cloud-Native 3-party 오픈소스 기능 제공)
- PaaS 특화 기능 (어플리케이션 통합 배포 / 컨테이너 이미지 레지스트리 제공)
- 멀티 클러스터 관리 기능 (친화적 UI)
3. 주요기능
사용자 편의성 극대화 GUI 기반 웹 콘솔
- 빌드 관리
- 컨테이너 이미지 관리 (컨테이너 레지스트리 기능 지원)
애플리케이션 빌드 배포에 최적화된 CI/CD 파이프라인
- CI/CD 파이프라인 리소스 등록 (소스코드, 이미지 등 파이프라인을 통해 필요한 리소스를 등록)
- CI/CD 파이프라인 구성 (Tekton 기반 -> 태스트 재사용성 증가 -> 여러 태스크를 조합해 구성 / 서비스 별 커스텀)
- CI/CD 파이프라인 실행
다양한 환경에서 Cloud Native Application 개발 지원
- 역할 기반 사용자 관리
- 워크로드 관리
기존 인프라 환경에 종속되지 않는 유연한 구성
- 오토 스케일링
모니터링 대시보드 기반 효율적인 플랫폼 통합 관리
- 모니터링 대시보드
컨테이너 인프라 환경에 대한 통합 운영관리
- 멀티 클러스터 관리
- 통합 로깅
4. SECloudit 아키텍처 구성 목록
| 구성 | 내용 |
| OpenShifgt | [플랫폼] - 쿠버네티스 기반의 기업용 컨테이너 애플리케이션 플랫폼입니다. |
| Kubernetes | [오케스트레이션] - 컨테이너화된 애플리케이션의 배포, 확장 및 관리를 자동화합니다. |
| Istio | [서비스 메시] - 마이크로서비스 간의 트래픽 관리, 보안 및 가시성을 제공합니다. |
| Tekton | [CI / 빌드] - 쿠버네티스 네이티브 환경에서 작동하는 클라우드 기반 CI 파이프라인 도구입니다. |
| Argo | [CD / 배포] - GitOps 방식을 통해 선언된 상태로 애플리케이션 배포를 자동화합니다. |
| CoreDNS | [네트워킹] - 쿠버네티스 클러스터 내에서 서비스 이름 해석을 위한 DNS 기능을 제공합니다. |
| Kiali | [관측성] - Istio 서비스 메시의 구조와 트래픽 흐름을 시각화하여 보여줍니다. |
| Calico | [네트워킹 / 보안] - 컨테이너 간의 네트워크 연결 및 보안 정책(Network Policy)을 관리합니다. |
| Nginx Ingress Controller | [네트워킹 / 게이트웨이] - 클러스터 외부의 HTTP/HTTPS 트래픽을 내부 서비스로 라우팅합니다. |
| Prometheus | [모니터링] - 시계열 데이터를 수집하고 경고(Alert)를 생성하는 모니터링 시스템입니다. |
| Fluentd | [로그 관리] - 여러 소스에서 로그를 수집하여 원하는 저장소로 전달하는 데이터 수집기입니다. |
| MySQL | [데이터베이스] - 정형 데이터 저장을 위한 널리 사용되는 오픈소스 관계형 데이터베이스입니다. |
| mongoDB | [데이터베이스] - 유연한 데이터 구조를 가진 비정형 데이터 저장용 NoSQL 데이터베이스입니다. |
| GitLab | [소스 제어 / CI] - 소스 코드 관리(Git)와 CI/CD 기능을 통합 제공하는 플랫폼입니다. |
| Harbor | [이미지 관리] - 컨테이너 이미지를 안전하게 저장하고 스캔하는 프라이빗 레지스트리입니다. |
| Docker | [컨테이너 런타임] - 애플리케이션을 컨테이너 단위로 빌드하고 실행하는 엔진입니다. |
| Distribution | [이미지 관리] - 컨테이너 이미지를 저장하고 배포하는 오픈소스 레지스트리 라이브러리입니다. |
| HELM | [패키지 관리] - 쿠버네티스 리소스를 차트(Chart) 단위로 관리하고 배포하는 도구입니다. |
Part2 : SECloudit 실습
1. Pod
- 쿠버네티스에서 컨테이너의 기본 단위로, 가장 기본적인 배포 단위이며 1개 이상의 컨테이너로 구성된 컨테이너 집합체.
- SECloudit에서의 Pod는 워크로드에 해당하며 생성은 yaml파일을 통해 쉽게 생성이 가능하다
[실습1] 아래와 같이 간단한 kym-pod를 생성할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: kym-pod
namespace: kym-ns
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80생성 시 pod의 상세 / yaml / 터미널 / 로그 / 모니터링 기능이 제공된다.


배포한 파드의 접근인 {KUBERNETES_IP}:{NODE_PORT} 다음과 같은 url로 접근이 가능하다.
[실습2] 이외에도 특정 동작을 수행하는 pod를 만들 수 있다.
apiVersion: v1 # 쿠버네티스 API 버전
kind: Pod # 리소스의 종류
metadata: # 리소스의 메타데이터
name: secloudit-pod # 리소스의 이름
namespace: secloudit-namespace # 리소스가 배포될 Namespace
spec: # Pod 내의 Container 상세 설정
containers: # Pod 안에 포함될 Container의 상세 설정
- image: busybox # 컨테이너 이미지
name: secloudit-container # 컨테이너 이름
env: # 환경 변수 목록 정의
- name: SECLOUDIT # 환경 변수 이름
value: "Platform as a service!" # 환경 변수 할당 값
command: ["/bin/sh"] # 컨테이너 실행 시 수행할 명령어
args: ["-c", "while true; do echo $(SECLOUDIT); sleep 10;done"] # 명령어 인자값위의 파드를 실행하고 로그를 확인해보면 SECLOUDIT 환경변수를 10초마다 계속 출력하는 모습을 볼 수 있다.

[실습3] 이외에 pod안에 여러 컨테이너도 만들 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: secloudit-pod
namespace: secloudit-namespace
spec:
containers:
- image: nginx
name: secloudit-container1
- image: redis
name: secloudit-container2
- image: memcached
name: secloudit-container3
- image: consul:1.15
name: secloudit-container4
2. ReplicaSet
- 클러스터 안에서 움직이는 파드의 수를 안정적으로 유지해주는 역할을 한다
- replicas의 수와 일치하는지 확인하여 가동중인 파드의 개수를 조절한다. (많으면 정지 / 없으면 생성)
- 또한 애플리케이션의 가용성을 보장하거나 부하를 분산시키기 위해서 사용된다.
[실습1] 아래와 같이 간단한 Replicas를 생성할 수 있다.
apiVersion: apps/v1 # 쿠버네티스 API 버전
kind: ReplicaSet # 리소스의 종류
metadata: # 리소스의 메타데이터
name: secloudit-replicaset # 리소스의 이름
labels: # ReplicaSet 자체의 레이블 정보
app: nginx # 리소스를 식별하고 파드와 연결하는 데 사용되는 키-벨류 쌍
spec: # ReplicaSet이 관리할 파드들의 템플릿
replicas: 3 # 실행할 Pod의 개수
selector: # ReplicaSet이 어떤 파드들을 관리해야하는지 식별하는 레이블셀렉터
matchLabels: # ReplicaSet이 어떤 파드를 관리해야하는지 레이블 지정
app: nginx # 연결할 Pod의 레이블 키-값
template: # ReplicaSet이 생성할 파드에 대한 템플릿
metadata: # Pod에 적용할 템플릿
labels: # Pod 레이블 지정
app: nginx # Pod의 레이블 키-값 쌍
spec: # Pod의 실제 동작 방식과 구성 설정
containers: # Pod안에 포함될 컨테이너의 상세 설정
- name: secloudit-container # 컨테이너 이름
image: nginx:latest # 컨테이너 이미지

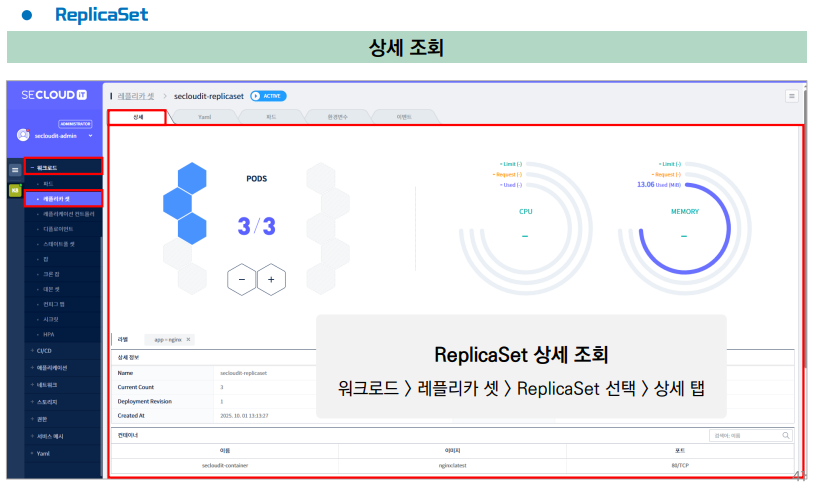
해당 ReplicaSet을 생성하면 3개의 Pod가 생성되며 해당 Pod의 개수는 3개가 유지된다.
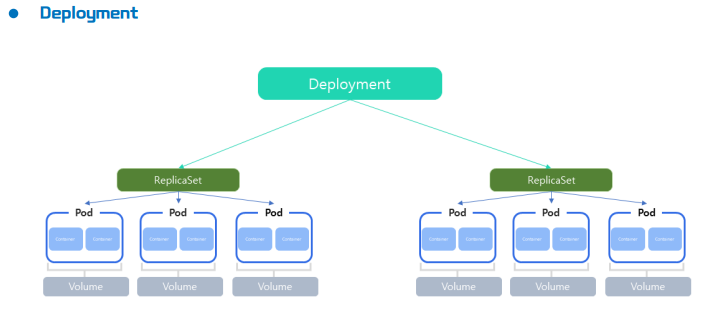
3. Deployment
- Deployment는 ReplicaSet의 상위 개념으로, Pod와 ReplicaSet에 대한 배포를 관리하는 역할을 한다.
- Pod와 ReplicaSet에 대한 선언적 업데이트를 제공한다.
[실습1] 아래와 같이 간단한 Deployment를 생성할 수 있다.
apiVersion: apps/v1 # 쿠버네티스 API 버전
kind: Deployment # 리소스 종류
metadata: # 리소스의 메타데이터
name: secloudit-deployment # 리소스 이름
namespace: secloudit-namespace # 리소스가 배포될 Namespace
labels: # ReplicaSet 자체의 레이블 정보
app: nginx # 리소스를 식별하고 파드와 연결하는데 사용되는 키-값으로 Replica와 같아야함!
spec: # Deployment가 관리할 파드의 템플릿
replicas: 3 # 실행할 Pod의 개수
selector: # Deployment가 어떤 파드를 관리해야하는지 레이블 지정
matchLabels: # 배포할 Pod의 레이블
app: nginx # 연결할 Pod의 레이블 키-값 쌍
template: # Deploymrnt가 생성할 파드에 대한 템플릿
metadata: # Pod에 적용할 템플릿
labels: # Pod 레이블 지정
app: nginx # Pod 레이블 키-값 쌍
spec: # Pod의 실제 동작 방식과 구성 설정
containers: # Pod안에 포함될 컨테이너 상세 설정
- name: secloudit-container # 컨테이너 이름
image: nginx:latest # 컨테이너 이미지
ports: # 컨테이너 포트 상세 설정
- containerPort: 80 # 컨테이너 포트번호
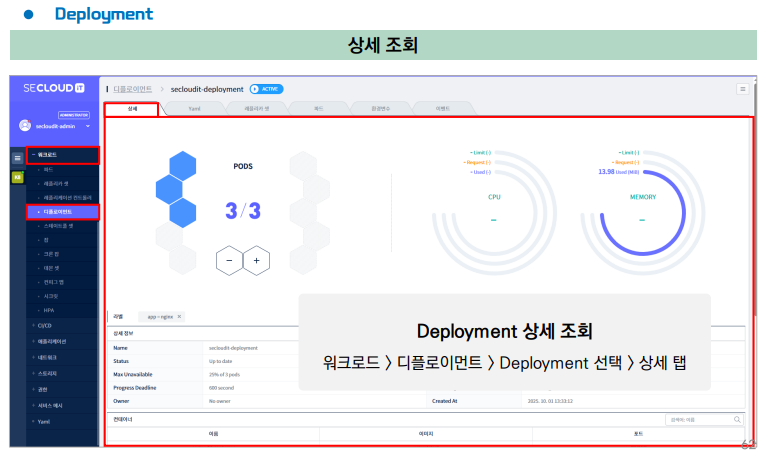
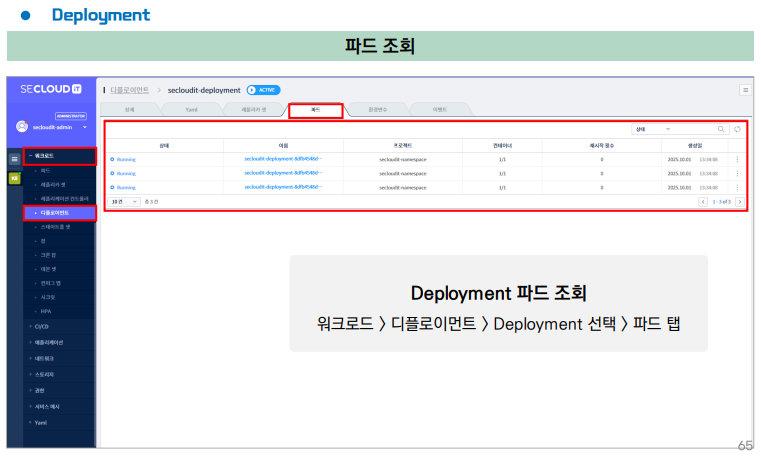
※ Deployment & ReplicaSet의 비교
사실 보면 대시보드나 yaml파일의 구성이 비슷하다.
하지만 Deployment는 ReplicaSet을 생성하는 역할을 하기 때문에 아래와 같은 차이들이 존재한다.
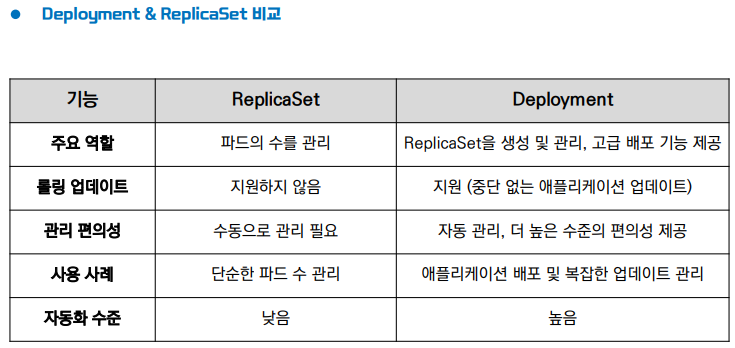
??? : Deployment만 생성하면 ReplicaSet은 알아서 만들어지니까 상관 없나?
??? : ReplicaSet만 생성하면 결국 똑같은 동작을 하는 거 아닌가?
-> ReplicaSet은 "숫자유지"가 핵심이고 Deployment는 "전략적 배포"가 핵심이다.
Deployment는 ReplicaSet의 상위 개념으로 여러개의 ReplicaSet을 관리하며 업데이트를 자동화한다.
Deployment를 통해 무중단 배포도 가능하고 롤백이나 배포 일시 중지등이 가능하다.
4. Job
- Job은 Pod의 일회성 작업을 실행하고, 작업이 성공적으로 완료되면 Pod가 종료된다
- 쉽게 우리가 일반적으로 알고 있는 Batch와 비슷한 역할을 하는 기능이다.
- Job에는 단일잡, 다중잡, 병렬잡 등이 존재한다.

[실습1] 아래와 같이 간단히 단일잡을 생성할 수 있다.
apiVersion: batch/v1 # 쿠버네티스 API 버전
kind: Job # 리소스의 종류
metadata: # 리소스의 메타데이터
name: secloudit-job # 리소스의 이름
namespace: secloudit-namespace # 리소스가 배포될 Namespace
spec: # Job이 생성될 때 실행할 작업의 사양 정의
template:
spec: # Job에서 생설될 Pod의 사양 정의
containers: # Pod안에 포함될 컨테이너 상세 설정
- name: secloudit-container # 컨테이너 이름
image: busybox # 컨테이너 이미지
command: ["echo", "Platform as a service!"] # Pod내에서 실행할 명령어
restartPolicy: Neve # 쿠버네티스 Job의 파드가 실패했을 때 재시작 정책

Job은 실행이 다 된 후에 알아서 Running이 아닌 Completed인 완료 상태로 바뀌며 종료된다.
[실습2] 이외에도 간단한 "Platform as a service!"를 출력하고 종료하는 Job을 만들어보자
apiVersion: batch/v1
kind: Job
metadata:
name: secloudit-job
namespace: secloudit-namespace
spec:
template:
spec:
containers:
- name: secloudit-container
image: busybox
command: ["echo", "Platform as a service!"]
restartPolicy: Never
[실습3] 이외에도 날짜를 출력하는 Job도 가능
apiVersion: batch/v1
kind: Job
metadata:
name: secloudit-job
namespace: secloudit-namespace
spec:
template:
spec:
containers:
- name: secloudit-container
image: busybox
args: ["date"]
restartPolicy: OnFailure # 실패했을 때만 재시작 정책
backoffLimit: 2 # 2번만 재시도 수행
5. CronJob
- CronJob은 정해진 스케줄에 따라 주기적으로 작업을 수행하는 역할을 한다
- 쉽게 우리가 알고 있는 스케쥴러로, 정해진 스케쥴에 Job을 생성해 실행하고 종료된다.
- 데이터 백업, 데이터 점검, 보고서 생성과 같은 주기적인 작업을 자동화하는데 사용된다.

[실습1] 아래와 같이 CronJob을 만들 수 있다.
apiVersion: batch/v1 # 쿠버네티스 API 버전
kind: CronJob # 리소스의 종류
metadata: # 리소스의 메타데이터
name: secloudit-cronjob # 리소스의 이름
namespace: secloudit-namespace # 리소스가 배포될 Namespace
spec: # Cronjob에서 생성될 Pod의 사양
schedule: "*/1 * * * *" # 스케쥴의 문자열
jobTemplate: # 생성될 Job 템플릿 정의
spec: # Job 템플릿 정의
template: # Job이 생설할 Pod의 템플릿
spec: # Job이 생성할 Pod의 상세 사양
restartPolicy: Never # Job의 Pod의 재시작 정책
containers: # Pod의 컨테이너 상세 설정
- name: secloudi-container # 컨테이너 이름
image: kubetm/init # 컨테이너 이미지
command: ["sh", "-c", "echo 'start';sleep 20; echo 'end'"] # 컨테이너 내 실행 명령어
terminationGracePeriodSeconds: 0 # Pod 종료까지의 유예시간
successfulJobsHistroyLimit: 2 # CronJob이 완료된 Job을 몇개까지 보관할지
failedJobsHistoryLimit: 1 # 실패 기록 작업을 몇개까지 유지할지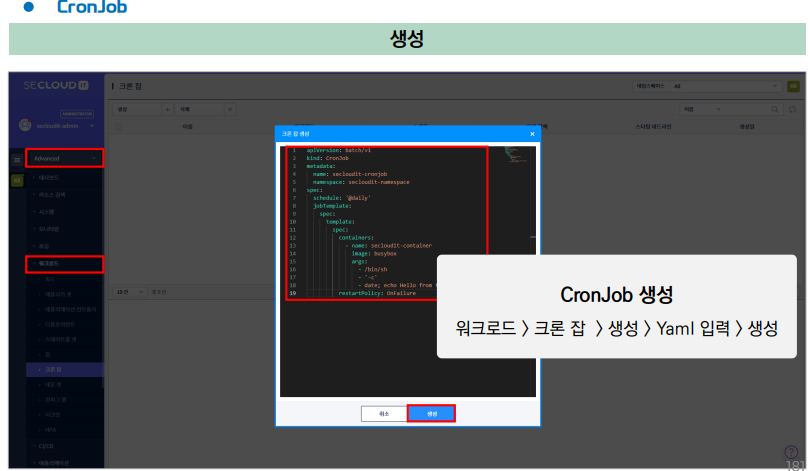
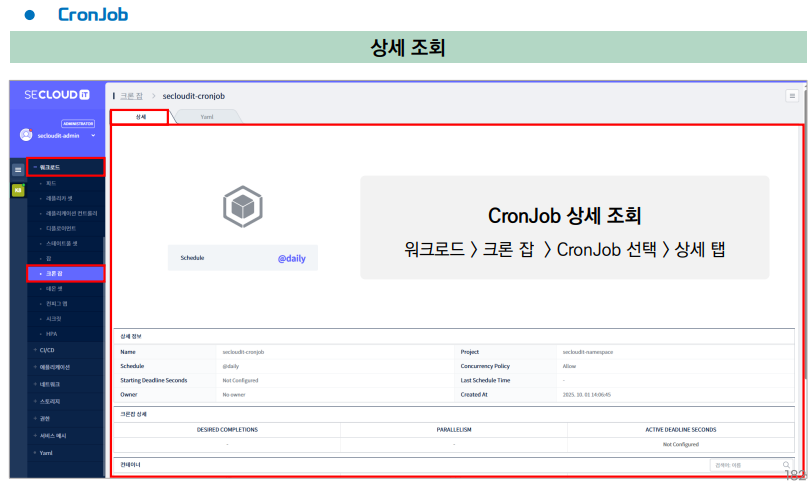

Cronjob은 정해진 스케쥴에 맞게 Job을 생성하고 Job은 작업에 맞게 Pod를 생성해 동작을 수행한다.
수행이 끝난 Job은 Completed상태가 되고 Job의 개수는 정해진 설정에 맞게 유지된다.
'Cloud' 카테고리의 다른 글
| [Cloud] - AWS Gen & Agentic AI (with. AWS Cloud 특강) (0) | 2026.01.04 |
|---|---|
| [Cloud] - CI/CD란? (with. AWS Cloud 특강) (0) | 2026.01.04 |
| [Cloud] - Cloud Native Application란? (0) | 2025.12.27 |
| [Cloud] - 쿠버네티스(Kubernetes) (with. AWS Cloud 특강) (0) | 2025.12.24 |
| [Cloud] - 쿠버네티스(Kubernetes)란? (0) | 2025.12.23 |